
 Моё обучение
Моё обучение Работы выпускников
Работы выпускников О проекте
О проекте Контакты
Контакты Отзывы
Отзывы



Руководство мошенника по чтению языка ассемблера (x86)
3 января 2023 г.
14 минут чтения
Ассемблерный код пугает людей. Для этого есть веская причина. Многим людям написание кода на языке ассемблера кажется равносильным написанию кода на древних дворфских рунах или вычислению числа пи римскими цифрами. Тот факт, что Roller Coast Tycoon почти полностью написан на ассемблере, звучит слишком удивительно, чтобы быть правдой. Многие программисты рассматривают язык ассемблера как сочетание древнего, загадочного, непостижимого, бесполезного и сложного.
Несмотря на все это, у меня есть секрет, которым я хочу поделиться с вами. Чтение языка ассемблера не настолько сложное. Ну, или, по крайней мере, это на порядок проще, чем писать на ассемблере. Есть несколько причин, почему это так, но прежде чем мы погрузимся в эту тему, позвольте мне сначала рассказать вам, почему вы должны заботиться о языке ассемблере.
Почему это должно меня волновать?
Для большинства людей, пишущих на языках, которые компилируются в собственный код, язык ассемблера представляет собой фундаментальные строительные блоки для каждой программы, которую мы создаем и запускаем1. Если вам когда-либо приходилось устранять неполадки в чем-то, где вы абсолютно, на 100%, ДОЛЖНЫ понимать, что делает строка кода… вам следует читать ассемблирование кода. Не читать исходный код C++, Rust или даже C. И причина этого в том, что исходный код на любом языке будет вам лгать. Не обязательно по вине языка программирования или компилятора, но в силу ограниченности нашего собственного понимания. Сложные или незнакомые особенности языка, неопределенное поведение или просто плохо написанный код может быть трудно понять, чтобы определить, что происходит на самом деле. Но ассемблерный код всегда скажет вам правду.
И кроме того, есть типичные случаи, когда вы читаете язык ассемблера: когда у вас нет исходного кода. Обратное проектирование чего-либо, чтобы понять, как это работает, не должно рассматриваться как недоступный навык. Это то, о чем должен иметь представление каждый программист, особенно если вы запускаете код в операционной системе с закрытым исходным кодом или используете библиотеки без исходного кода.
Но самое главное, понимание языка ассемблера необходимо для понимания того, как все работает на самом деле, и может дать вам лучшее представление о том, как все работает, независимо от того, создаете ли вы системы или разрушаете их. Чтение языка ассемблера не является заменой соответствующих инструментов обратного проектирования, таких как Ghidra или IDA, но это необходимый дополнительный навык.
Почему читать легче, чем писать
Одной из самых сложных частей языка ассемблера является тот факт, что существует так много различных инструкций. Набор инструкций 8086 начинался с 81 различной инструкции. В современном процессоре Intel это число ближе к 1000. Вы можете себе представить, что попытка найти правильную инструкцию для конкретной ситуации будет сложной. На самом деле количество инструкций, которые вам нужно научиться читать, довольно мало. В одном двоичном файле, который я просмотрел, 83% используемых инструкций были 10 наиболее часто встречающимися инструкциями, а многие из 30 наиболее часто встречающихся инструкций являются лишь небольшими вариациями (например, И и ИЛИ).
Вот диаграмма, которую я сделал, показывающая относительную частоту 30 наиболее распространенных типов инструкций, которые я видел в одном двоичном файле. Я подозреваю, что вы увидите аналогичный график на других архитектурах, но на x86 вы увидите особенно длинный хвост из-за большого количества типов инструкций. Вы можете понять очень большой кусок ассемблерного кода, если будете знать только самые распространенные инструкции.
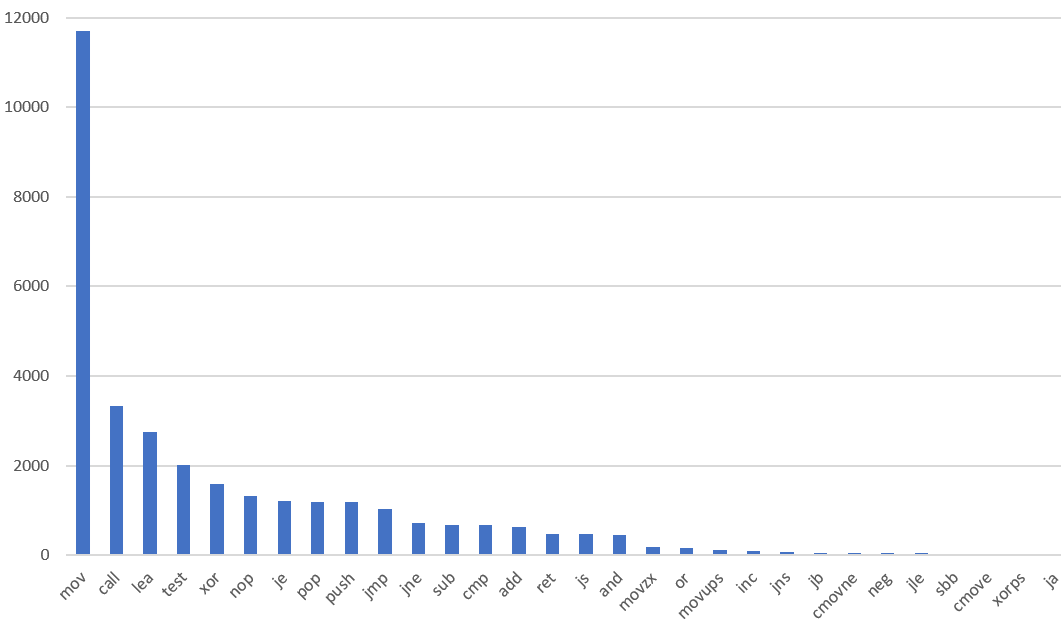
Как читать ассемблер
Надеюсь, я убедил вас, что научиться читать на ассемблере важно и не так сложно, как вы думаете. Итак, позвольте мне дать вам небольшой ускоренный курс по ассемблеру x86.
Два вида: синтаксис AT&T и Intel.
По историческим причинам существует два «вкуса» синтаксиса дизассемблирования для x86. Один называется «Intel», а другой — «AT&T». Если вы живете в мире Windows, возможно, вы никогда не увидите синтаксис AT&T, но некоторые инструменты с открытым исходным кодом по умолчанию используют синтаксис AT&T, поэтому полезно распознавать, когда вы имеете дело с ним.
Самая большая разница, которую вы увидите между двумя этими вариантами, заключается в том, что порядок операндов обратный! Вот пример синтаксиса AT&T:
addl $4, %eax
А вот пример синтаксиса Intel:
add eax, 4
Кроме того, что порядок меняется местами, константы также имеют префикс $, а регистры — префикс %. К некоторым мнемоникам также добавляется буква для обозначения размера операндов, например, l для 32-битных операндов.
В зависимости от инструментов, которые вы используете, у вас может не быть выбора, какой синтаксис использовать. Например, WinDbg поддерживает только синтаксис Intel. Многие инструменты с открытым исходным кодом по умолчанию используют синтаксис AT&T, но у них есть возможность включить синтаксис Intel. Для objdump вы можете использовать -M intel. Например:
objdump -d -M intel ./a.out
Хотя я уверен, что у кого-то есть аргументы в пользу синтаксиса AT&T, я бы посоветовал избегать его по одной простой причине: в руководстве Intel (SDM) используется синтаксис Intel, и это важный ресурс для понимания того, как работает инструкция. Поэтому, чтобы избежать путаницы, придерживайтесь синтаксиса Intel.
Части инструкции: мнемоника, операнды и префиксы
Единая единица языка ассемблера — это «инструкция», состоящая из трех частей.
«Мнемоника» — это имя инструкции, например «ADD» или «MOV», которое сообщает вам, что делает инструкция. Большинство мнемоник представляют собой сокращенную версию слова, например MOV (move - перемещение), SUB (subtract - вычитание) или INC (increment - инкремент, приращение). Другие операции имеют аббревиатуру мнемоники, например, LEA (Load Effective Address - Загрузка Эффективного Адреса) или SAL (Shift Arithmetic Left - Арифметический Сдвиг Влево). Существуют сложные инструкции, работающие с «векторами» (также известные как SIMD или Single Instruction Multiple Data), которые, как правило, имеют длинные и сложные имена, но, к счастью, вам не придется слишком часто читать такие вещи, как PMADDUBSW (умножение знаковых и беззнаковых байтов, сложение горизонтальной пары знаковых слов, упаковка насыщенных знаковых слов).
Каждая инструкция может иметь от 0 до 3 операндов, хотя чаще всего используется 2 операнда. Операнды могут быть регистрами, константами или ячейками памяти, но не каждый тип и комбинация типов операндов доступны для каждой инструкции. Например, нет версии MOV, которая занимает две ячейки памяти, но MOV reg, mem и MOV mem, reg доступны для перемещения данных.
Для инструкций, которые принимают хотя бы один операнд, первый операнд часто является местом назначения для записи данных и, как правило, также источником. Инструкция INC EAX считывает значение EAX, добавляет единицу и записывает значение обратно в EAX. Любые операнды после первого обычно только считываются, но не записываются. Одним заметным исключением из этого правила является инструкция XCHG, которая может поменять местами два регистра или регистр и ячейку памяти.
Инструкции также могут иметь «префиксы», которые изменяют поведение инструкции. Два типа, с которыми вы, скорее всего, столкнетесь, это LOCK для выполнения определенных операций чтения/изменения/записи атомарными и REP/REPZ/REPNZ, которые используются для «строковых» операций копирования/сравнения последовательности байтов.
Операнды памяти
У Intel есть гибкий (и сложный) набор режимов адресации памяти. К счастью, при чтении кода вам не нужно знать большую часть этого, потому что с синтаксисом Intel адресное выражение всегда будет описываться как простое выражение, такое как:
mov rbp,[rsp-170h]
Самые сложные выражения могут содержать два регистра, константу и «масштабный коэффициент» для одного из регистров. Например:
mov rax,dword ptr [rbp+rcx*4+1234h]
Одной из специальных инструкций, которая принимает адрес памяти, является инструкция LEA, что означает Load Effective Address. В отличие от любой другой инструкции, которая принимает операнд памяти, эта не читает и не записывает адрес, а только вычисляет эффективный адрес, по которому будет выполняться загрузка или сохранение в память. На самом деле нет причин, почему адрес должен быть именно ячейкой памяти, поэтому вы иногда видите, как LEA используется для объединения нескольких арифметических операций вместе, т.к. иногда одна инструкция LEA выполняется быстрее, чем несколько инструкций ADD.
Регистры
Набор регистров x64 включает указатель инструкций (RIP) и 16 регистров общего назначения (RAX, RCX, RDX, RBX, RSP, RBP, RSI, RDI, R8-R15)3. Под «Общего Назначения» мы подразумеваем, что их можно использовать для хранения всего, что вы хотите. Например, инструкция MOV может использоваться для перемещения значений в/из любого из регистров общего назначения, но не может напрямую обращаться к указателю инструкции, RIP. Хотя они могут использоваться для общих целей, некоторые из регистров имеют особое назначение и неявно используются определенными инструкциями. Например, регистр RSP всегда используется с любой операцией, касающейся стека, например с инструкциями CALL и PUSH. Инструкции RSI и RDI неявно используются для любых «операций со строками», таких как MOVS. Некоторые регистры просто более эффективны для использования в определенных случаях, но при чтении ассемблерного кода вам обычно не нужно об этом беспокоиться.
Хотя все эти регистры 64-битные, x86 может использовать меньшие части большинства регистров, и мы используем другое имя, когда говорим о меньших частях регистров. EAX — это младшие 32 бита RAX. AX — это младшие 16 бит RAX. AL — младшие 8 бит RAX. И у нас также есть AH, который можно использовать для описания старших 8 бит AX. В общем, вы можете использовать их для управления битами большего регистра, например, используя MOV AX, 0, чтобы очистить младшие 16 бит RAX. Единственное странное исключение состоит в том, что запись в младшие 32 бита 64-битного регистра очистит старшие 32 бита до 0.
0:000> rrax=1234567812345678
0:000> u . L2
00007ffb`a8980959 b834120000 mov eax,1234h
00007ffb`a898095f cc int 3
0:000> rrax
rax=1234567812345678
0:000> p
00007ffb`a898095e cc int 3
0:000> rrax
rax=0000000000001234
Обратите внимание, что существует множество других регистров, включая регистры сегментов, регистры отладки и регистры управления. Если вы только начинаете читать дизассемблирование, вам пока не нужно беспокоиться об этом. Сегментные регистры могут влиять на то, как обрабатывается загрузка и сохранение памяти. Регистры отладки используются, чтобы вызвать исключение для определенных адресов памяти (например, прерывание при чтении памяти по определенному адресу). Регистры управления используются из режима ядра для управления конфигурацией системного уровня.
Общие инструкции
Наиболее распространенной инструкцией на порядок чаще является инструкция MOV. Она может использоваться для чтения памяти, записи памяти и копирования данных между регистрами. Поскольку синтаксис Intel помещает назначение как левый операнд, инструкцию MOV A, B можно рассматривать, просто как оператор присваивания A = B.
Инструкция CALL предназначена для вызова функции. Это может быть прямой адрес или косвенный адрес, при котором местоположение целевой функции хранится в регистре или памяти, что полезно для таких случаев, как таблицы функций. Фактическое поведение инструкции CALL состоит в том, чтобы взять текущий указатель инструкции, поместить его в стек, а затем заменить текущий указатель инструкции значением первого операнда.4. Инструкция RET (return) делает прямо противоположное и выталкивает значение из стека в текущий указатель инструкции. Инструкция JMP аналогична CALL, за исключением того, что она не помещает адрес возврата в стек. Обычно она используется для управления потоком внутри функции.
Есть также набор логических и арифметических операций, которые выполняются по стандартной схеме. К ним относятся ADD dest, src, SUB dest, src, AND dest, src и XOR dest, src. Их куча, и все они работают практически одинаково. ADD RAX, RBX в псевдокоде будет RAX = RAX + RBX. В дополнение к установке пункта назначения на результат операции они также устанавливают ряд «флажков» на основе операции. Например, «нулевой флажок» устанавливается, если результат был нулевым. Флаги важны, потому что они контролируют все условные операции. Например, JZ (Jump if Zero) — это прыжок, зависящий от нулевого флага. Если установлен нулевой флаг, ЦП начнет выполнение инструкций по адресу, указанному в качестве операнда. Если нет, он продолжит выполнение инструкций, следующих за JZ. Эта же инструкция имеет другое название JE (Jump if Equal). Это немного говорит вам о том, почему этот флаг полезен. Если вы хотите проверить, равны ли два значения, вы можете вычесть их и посмотреть, равен ли результат нулю. И на самом деле это именно то, чем является инструкция CMP first, second. Это инструкция SUB, но без сохранения данных обратно в первый операнд. Дело в том, что он установит все флаги, как если бы он сделал вычитание, но не сохранит результат. Используя другие флаги, мы можем выполнять другие условные переходы, такие как JNE (Jump if Not Equal), JB (Jump if Below), JLE (Jump if Less or Equal). Обратите внимание, что есть некоторые инструкции с очень похожими названиями, такие как JB (Jump if Below) и JL (Jump if Less), и разница в том, что JB используется для беззнаковых сравнений, а JL — для сравнений со знаком. Существует множество различных условных переходов, но наиболее часто встречаются JE (также известный как JZ) и JNZ (также известный как JNE). Вы увидите некоторую комбинацию JB, JS, JL и других в зависимости от того, использует ли программа больше чисел со знаком или без знака.
Подобной инструкции CMP является инструкция TEST, которая также устанавливает флаги без записи в регистр назначения, но здесь выполняется операция AND вместо вычитания. Как следует из названия, эта инструкция обычно используется для проверки того, установлен ли какой-либо бит.
Есть несколько инструкций, которые принимают один операнд. DEC и INC будут уменьшать или увеличивать регистр (или ячейку памяти), в то время как NEG инвертирует число (дополнение до двух), а NOT инвертирует каждый бит регистра или ячейки памяти.
Инструкция NOP… ничего не делает. Это сокращение от «No OPeration». Хотя у компиляторов есть несколько вариантов использования этой инструкции, один из них пригодится, когда вы хотите отключить небольшой фрагмент кода (что мы иногда называем «за-NOP-ить»).
Последняя распространенная инструкция, о которой я упомяну, это инструкция INT. Она всегда принимает постоянный операнд в виде однобайтового значения. Это сокращение от «INTerrupt» и используется для запуска «программного прерывания», которое переключает ЦП в режим ядра и запускает код, соответствующий номеру прерывания (обработчик прерывания). Двумя важными вариантами использования являются точки останова (которые всегда являются INT 3) и вызовы системы/ядра, хотя последнее применение было в основном заменено инструкциями SYSCALL/SYSENTER, поскольку они лучше подходят для этой цели.
Видите, это не так сложно!
Если вы дошли до этого места, у вас должна быть основная информация, необходимая для понимания кода ассемблера. Лучший способ пройти этот этап — начать читать код, сгенерированный компилятором. Лучший способ сделать это для примеров программ — использовать Compiler Explorer, который аккуратно раскрасит взаимосвязь между исходным кодом и сборкой. Я также думаю, что очень полезно пройтись по ассемблерному коду и посмотреть, как меняются регистры. Для этого WinDbg является моим предпочтительным инструментом, но любой отладчик, который может работать на уровне сборки (а не на уровне исходного кода!), даст вам аналогичный опыт. Наконец, если вы хотите по-настоящему понять каждую деталь того, как работает инструкция, убедитесь, что вы загрузили последнюю копию Руководства для разработчиков программного обеспечения Intel, которое мы обычно называем просто «SDM». Он невероятно плотный, но содержит каждую деталь каждой инструкции, а также все остальное, что вы можете себе представить о низкоуровневом программировании x86 и x64.
Было ли это полезно? Есть вопросы, на которые здесь нет ответа? Я сделал какие-то ошибки? Дайте мне знать в Twitter или Mastodon!
Сноски
- Я не собираюсь разделять понятия “ассемблер” и “машинный код”. Если вам важно это различие, этот пост, вероятно, не очень актуален для вас. То же самое происходит, если вы хотите говорить о микрокоде вместо машинного кода.
- На самом деле не существует инструкций x86 с двумя явными операндами памяти! Существуют инструкции, которые могут читать из одного адреса памяти и записывать в другой, но один из этих адресов будет неявным через какой-то другой регистр. Например, инструкция PUSH [адрес] может прочитать значение из одного адреса, а затем записать его в текущий указатель стека.
- Те из вас, у кого острый глаз, заметят, что я перечислил RAX, RCX, RDX, RBX, а не RAX, RBX, RCX, RDX. Это потому, что RAX, RCX, RDX, RBX — это правильный порядок регистров, и почти все ошибаются в диаграммах в Интернете. На самом деле это не важно в 99% случаев, но если вы посмотрите любое место, где регистры индексируются или хранятся в памяти, то всегда такой порядок.
- Чтобы быть более точным, операнд оценивается и сохраняется как временное значение, а затем указатель инструкции помещается в стек. Это важно, если операнд ссылается на RSP! В первый раз, когда я написал эмуляцию ЦП для этого, работая над Time Travel Debugging, я ошибся. Казалось, что все работает нормально, но когда некоторые программы переходили на неправильный адрес, происходил случайный сбой!

 Предварительный просмотр Stateful Вью в SwiftUI
Предварительный просмотр Stateful Вью в SwiftUI
