
 Моё обучение
Моё обучение iOS-Инкубатор
iOS-Инкубатор Работы выпускников
Работы выпускников О проекте
О проекте Контакты
Контакты Отзывы
Отзывы



Как избежать скрытых опасностей: обход неочевидных ловушек в машинном обучении (ML) на iOS
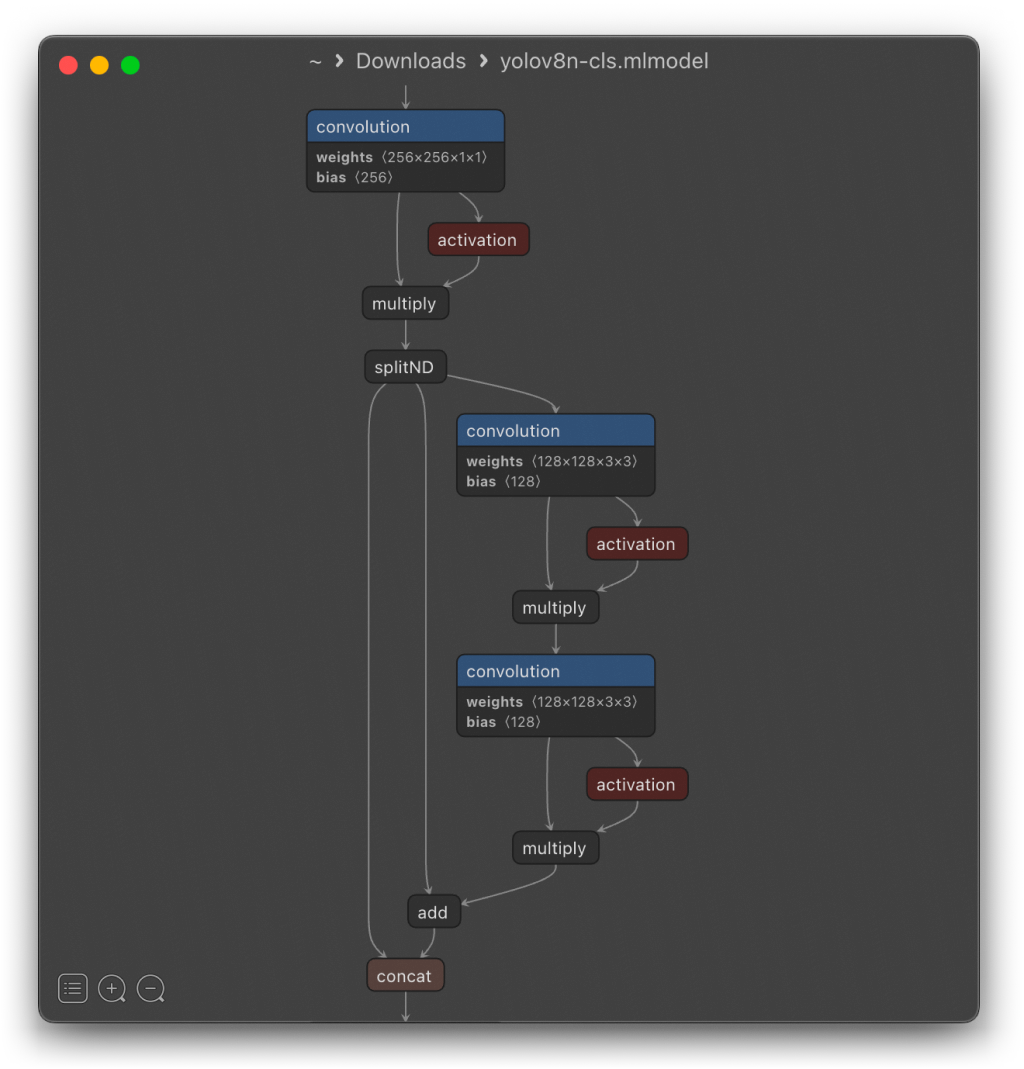
Скриншот Netron графа модели yolov8n-cls
Вам необходимо МЛ?
Машинное обучение отлично выявляет наблюдения. Если вам нужен чистый набор данных для вашей задачи, то это обычно только вопрос времени, когда вы можете построить модель ML со сверхчеловеческой производительностью. Это особенно верно в классических задачах, таких как классификация, регрессия и обнаружение аномалий.
Когда вы будете готовы решить некоторые из своих бизнес-задач с помощью ML, вы должны подумать, где будут работать ваши модели ML. В некоторых случаях имеет смысл использовать серверную инфраструктуру. Преимущество серверной достоверности в том, что ваши модели ML показали конфиденциальность, поэтому конкурентам будет труднее вас догнать. Кроме того, серверы могут работать с более высоким спектром моделей. Например, модели GPT (прославившиеся благодаря ChatGPT) в настоящее время требуются современные графические процессоры, поэтому о потребительских устройствах не может быть и речи. С другой стороны, обслуживание вашей конфиденциальной информации обходится довольно дорого, и если потребительское устройство может работать с вашей моделью, зачем больше? Кроме того, могут возникнуть проблемы с конфиденциальностью, когда вы не можете отправить данные на удаленный сервер для обработки.
Однако давайте предположим, что имеет смысл использовать устройства iOS ваших клиентов для запуска моделей ML. Что может пойти не так?
Ограничения платформы
Ограничения памяти
У устройств iOS гораздо меньше доступной видеопамяти, чем у их настольных продуктов. Например, недавно выпущенная видеокарта Nvidia RTX 4080 Ti имеет 20 ГБ доступной памяти. iPhone, с другой стороны, имеет видеопамять, часто встречается с фрагментами оперативной памяти, в так называемой «унифицированной памяти» (унифицированной памяти). Для справки: на iPhone 14 Pro 6 ГБ оперативной памяти. Более того, если вы выделите больше половины памяти, iOS, скорее всего, купит приложение, чтобы убедиться, что операционная система останется работоспособной. Это означает, что у вас есть доступ к 2-3 ГБ памяти для вывода нейронной сети.
Исследователи обычно тренируют свои модели, чтобы предположить предположение по воспроизведению памяти. Тем не менее, также были выявлены случайные скорости и объемная память, поэтому вы можете либо искать менее требовательные модели, либо обучить их самостоятельно.
Поддержка сетевых уровней (операций)
Большинство методов ML и нейронных сетей основаны на языках глубокого обучения, а затем конвертируются в модели CoreML с помощью Core ML Tools . CoreML — это механизм логического вывода, написанный компанией Apple, который может запускать различные модели на устройствах Apple. Уровни хорошо рассчитаны для аппаратного обеспечения, список обеспеченных уровней довольно длинный, так что это отличная отправная точка. Однако возможны и другие варианты, такие как Tensorflow Lite .
Лучший способ увидеть возможности с CoreML — это посмотреть на некоторые уже преобразованные модели с помощью средств просмотра, таких как Netron . Apple перечисляет некоторые из имеющихся моделей , но есть и модельные зоопарки, созданные сообществами. Полный список доступных операций постоянно меняется, поэтому просмотр исходного кода Core ML Tools может быть полезен в качестве отправной точки. Например, если вы хотите преобразовать модель PyTorch, вы можете найти нужный уровень здесь .
Кроме того, некоторые новые архитектуры имеют записанный от руки код CUDA для некоторых уровней. В природе таких вы не можете ожидать, что CoreML связывает предопределенный уровень. Тем не менее, вы можете выбрать свою идеальную удачу , если у вас есть опытный инженер, знакомый с написанием кода GPU.
В целом, лучший совет здесь — преобразование вашей модели в CoreML как можно раньше, ещё до её обучения. Если у вас есть модель, которая не была преобразована сразу, можно изменить определение нейронной сети в вашей платформе DL или в исходном коде преобразования Core ML Tools, чтобы сгенерировать допустимую модель CoreML без необходимости записи пользовательского уровня для вывода CoreML.
Проверка
Ошибки механизма вывода
Невозможно протестировать любую возможную настройку уровней, поэтому выход всегда будет иметь какие-то ошибки. Например, часто можно увидеть, что расширенные свёртки (разветвления) используют слишком много памяти с CoreML, что, вероятно, страдает от плохо написанной оценки с большим значением, заполненным нулями. Другой ошибочной ошибкой является вывод модели для некоторых архитектурных моделей.
В этом случае может иметь место порядок операций. Возможны неверные результаты в зависимости от того, что раньше происходит: активация со свёрткой или остаточное соединение. Наиболее реальный способ получения результатов, который всё работает правильно — это взять вашу модель, использовать её на нужном вычислении и сравнить результаты с настольной общественностью. Для этого полезно использовать хотя бы полуобученную модель, иначе случайные ошибки могут накапливаться для случайно сильно возбужденных моделей. Несмотря на то, что окончательная обучаемая модель будет работать нормально, результаты могут сильно преуспеть между игрой и настольным компьютером для случайной гоночной модели.
Потеря ценности
iPhone широко использует половинную гипотезу для сопоставления выводов. В то время как некоторые модели не имеют заметных признаков заболевания из-за меньшего количества битов в представлении с плавающей запятой, другие могут пострадать. Вы можете аппроксимировать ценность, оценив свою модель на рабочем столе с половинной точностью и вычислив тесты метрику для своей модели. Еще лучший метод — его воспроизведение на изображении, чтобы добиться, насколько точна модель, как воспроизвести.
Профилирование
Различные модели iPhone обладают разными аппаратными возможностями. Последние имеют улучшенные особенности обработки Neural Engine, которые значительно повышают производительность. Они вычисляют для конкретных операций, а CoreML осуществляет разумную работу между ЦП, ГП и Neural Engine. Графические процессоры Apple также улучшались с течением времени, поэтому естественно присутствие производительности на разных моделях iPhone. Стандарт протестирует свои модели на приемлемых устройствах, чтобы обеспечить соответствие требованиям и приемлемую производительность для устройств.
Также стоит отметить, что CoreML может выявить некоторые промежуточные уровни и требования на месте, что может значительно повысить производительность. Еще один фактор, который следует учитывать в том, что иногда модель, которая хуже работает на настольном компьютере, на самом деле может быстрее выполнять сбор данных на iOS. Это означает, что стоит потратить время на эксперименты с локальными архитектурами.
Для ещё большей эффективности в Xcode есть хороший инструмент Инструменты с шаблоном только для моделей CoreML, который может дать более полное представление о том, что кратко излагает вывод вашей модели.
Заключение
Никто не может предусмотреть все возможные подводные объекты при разработке моделей ML для iOS. Однако есть некоторые ошибки, которых можно избежать, если знать, что искать. эффективно преобразовывать свои модели, исследовать и профилировать модели ML, чтобы быть уверенными, что ваша модель будет работать и соответствовать вашему бизнес-требованию правильно, и отслеживать советы, изложенным, успех как можно быстрее.

 Эволюция архитектуры приложения Facebook для iOS
Эволюция архитектуры приложения Facebook для iOS
