
 Моё обучение
Моё обучение Работы выпускников
Работы выпускников О проекте
О проекте Контакты
Контакты Отзывы
Отзывы



Заметка
Данное учебное пособие предполагает, что вы используете Xcode 9 Beta 1 или более поздней версии, Swift 4 и iOS 11.
На сегодняшний день машинное обучение является одним из самых популярных направлений. Многие об этом слышали, но мало кто знает, что это такое на самом деле.
В рамках iOS, данный учебный материал по машинному обучению познакомит вас с двумя совершенно новыми фреймворками, это Core ML и Vision, которые были представлены в iOS 11.
Также вы узнаете многое, о том как работать с новым API данных фреймворков при помощи модели Places205-GoogLeNet ( см.[1] ), которая предназначена для классификации сцен изображения.
[1] Places205-GoogLeNet - готовая модель, которая распознает сцены изображений из 205 категорий, таких как терминал аэропорта, спальня, лес, берег и многое другое.
Поехали!
Для начала скачайте стартовый проект.
Проект уже содержит пользовательский интерфейс для отображения изображения и позволяет пользователю выбрать изображение из своей библиотеки фотографий. Таким образом, вы сможете сосредоточиться на реализации машинного обучения и основных деталях приложения.
Если проект скачан, самое время его запустить. На экране вы увидите изображение ночного города и кнопку:
Выберите любое другое изображение из библиотеки фотографий в вашем приложении. В Info.plist данного проекта уже установлены все необходимые настройки для загрузки фотографий в вашем приложении «Privacy – Photo Library Usage Description». Вам останется лишь дать согласие на доступ приложению к вашим фотографиям.
Разрыв между изображением и кнопкой содержит текстовый label (UILabel), где будут отображены модели классификации сцен изображениий.
Машинное обучение в iOS
Машинное обучение является одним из видов искусственного интеллекта, где компьютеры «учатся сами», будучи еще не запрограммированными на действия, которые они умеют, после своего «обучения». Вместо разработки алгоритма, силами машинного обучения можно позволить компьютерам самим разрабатывать и совершенствовать какие-либо алгоритмы, производить поиск паттернов в больших объемах данных.
Глубокое обучение
С 1950-х годов исследование в мире искусственного интеллекта разработало множество подходов компьютерного обучения. Ядро Core ML от Apple поддерживает нейронные сети, деревья решений (tree ensembles - древовидный алгоритм принятия решений), метод опорных векторов (support vector machines), обобщенные линейные модели (generalized linear models), генерация признаков (feature engineering) и пайплайн модели (pipeline models). Стоит заметить, что с помощью нейронных сетей уже реализовано многое, например из последних громких событий, начиная с 2012 года, Google использует видео в YouTube, для чтобы обучить его искусственному интеллекту по распознаванию кошек и людей. Через пять лет, Google уже спонсирует конкурс, задача которого определить 5000 видов растений и животных. Такие приложения, как Siri и Alexa, также появились на свет, благодаря существованию нейронных сетей.
Задача нейронных сетей смоделировать мозговые процессы человека, представляя собой слои узлов, которые по-разному соединены между собой. Каждый такой дополнительный слой требует большого увеличения вычислительной мощности, например: Inception v3, модель распознавания объекта, имеет 48 слоев и около 20 миллионов параметров. Но расчеты – это в основном умножение матриц, с которыми GPU (графический процессор) справляется очень эффективно. В последнее время, на фоне снижения стоимости GPU (графический процессор) позволяет исследователям создавать многослойную глубокую нейронную сеть, отсюда и появился термин “глубокое обучение”.
Нейронная сеть, примерно 2016 г.
Нейронным сетям необходимо предоставлять большое количество входных данных, желательно, чтобы эти данные предоставляли весь возможный спектр данных. Как раз на само появление машинного обучения и повлиял большой рост пользовательских данных. Обучение модели означает, что вы предоставляете данные для обучения нейронным сетям, а далее они сами вычисляют необходимую формулу для комбинирования входных параметров и получение уже выходных данных. Обучение происходит в автономном режиме, как правило, на компьютерах, которые содержат большое количество GPU (графических процессоров).
Для того, чтобы использовать эту модель, вам необходимо дать ей новые входные данные, и она вычислит выходные данные/результат: это называется логическим выводом. Вывод также производит большое количество вычислений, для вычисления результата от новых входных данных. Выполнение этих вычислений на портативных устройствах стало возможным благодаря таким фреймворкам, как Metal.
В конце этого туториала вы увидите, что “глубокое обучение” пока что далеко от идеала. На самом деле сложно создать действительно полный набор данных для обучения, и в тоже время во много раз проще “переучить” модель, так что она будет придавать слишком большой вес ненадежным параметрам.
Что предлагает нам Apple?
Apple представила NSLinguisticTagger еще в iOS 5 для анализа естественного языка. Metal пришел уже в iOS 8, обеспечивая низкоуровневый доступ к GPU (графическому процессору) устройства.
В прошлом году Apple добавила базовые подпрограммы нейронных сетей (Basic Neural Network Subroutines - BNNS) в свою инфраструктуру Accelerate, что позволило разработчикам создавать нейронные сети для логического вывода (не обучения).
И уже в этом году Apple предоставила вам Core ML и Vision!
- Core ML - упрощает использование обучаемых моделей в ваших приложениях.
- Vision - дает вам легкий доступ к моделям от Apple для распознания лиц, ориентиров, текста, прямоугольников, штрих-кодов и объектов.
Вы также можете обернуть любую модель анализа изображений Core ML в модели Vision, что кстати и сделаем в этом обучающем уроке. Поскольку эти две структуры построены на Metal, они позволяют эффективно работать на устройстве и вам не потребуется отправлять данные пользователей на сервер.
Интеграция Core ML в ваше приложение
Мы с вами воспользуемся моделью Places205-GoogLeNet, которую можете загрузить с веб-страницы Apple - Machine Learning. Прокрутите вниз до раздела «Working with Models» и загрузите Places205-GoogLeNet. Обратите также внимание на другие три модели, которые могут распознать уже все объекты – деревья, животные, люди и т.д. – распознание происходит в изображениях.
Заметка
Если у вас есть подготовленная модель, созданная с помощью поддерживаемых инструментов для машинного обучения, таких как Caffe, Keras или scikit-learn, Преобразование обучаемых моделей в Core ML (Converting Trained Models to Core ML) - описывает, как вы можете преобразовать его в формат Core ML
Добавление модели в ваш проект
Если вы уже скачали GoogLeNetPlaces.mlmodel перетащите его из Finder в группу Resources в Project Navigator вашего проекта как это показаны на изображении ниже:
Нажмите на этот файл, и подождите некоторое время. Появится стрелка в разделе «Model class», рядом с GoogLeNetPlaces, когда Xcode сгенерирует класс модели, подробнее на изображении:
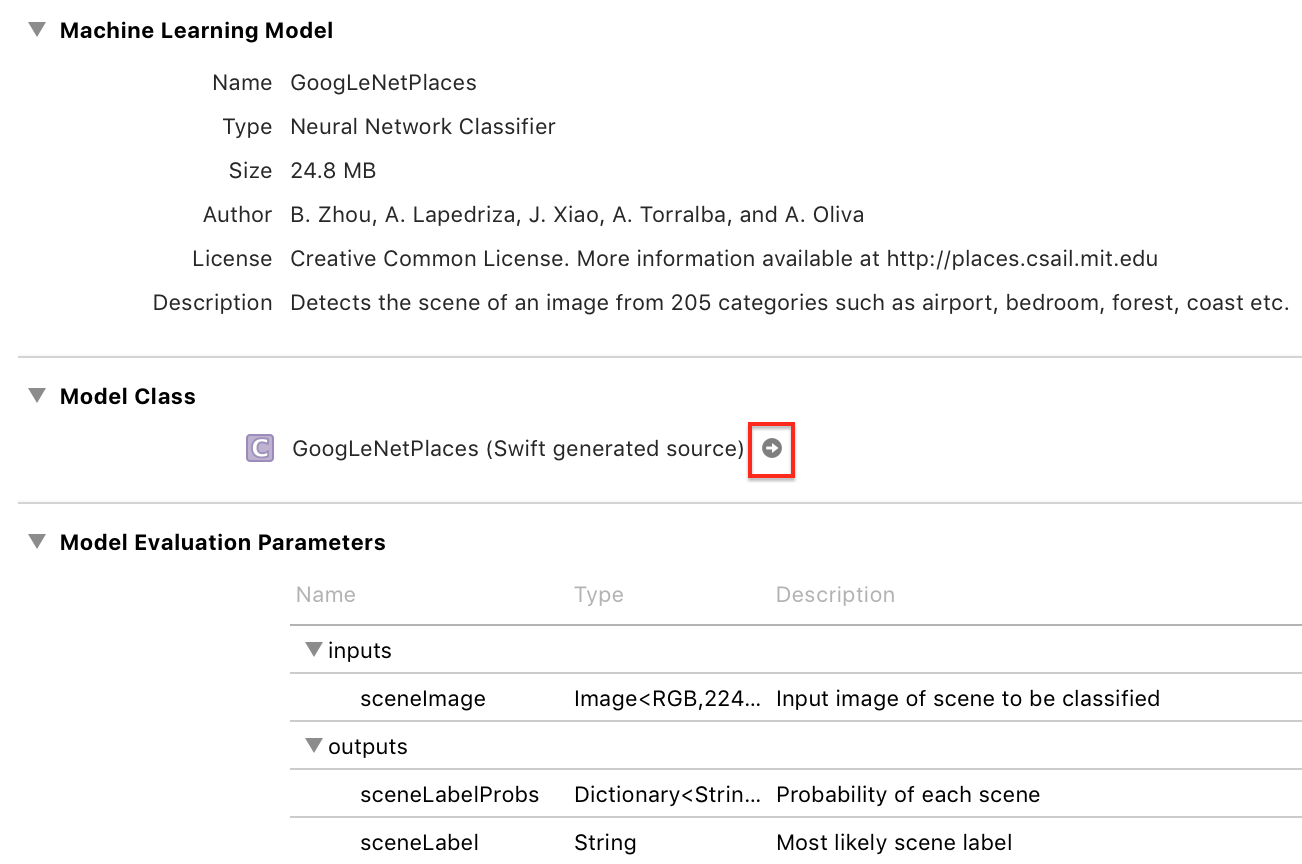
Нажмите на стрелку, чтобы увидеть сгенерированный класс:
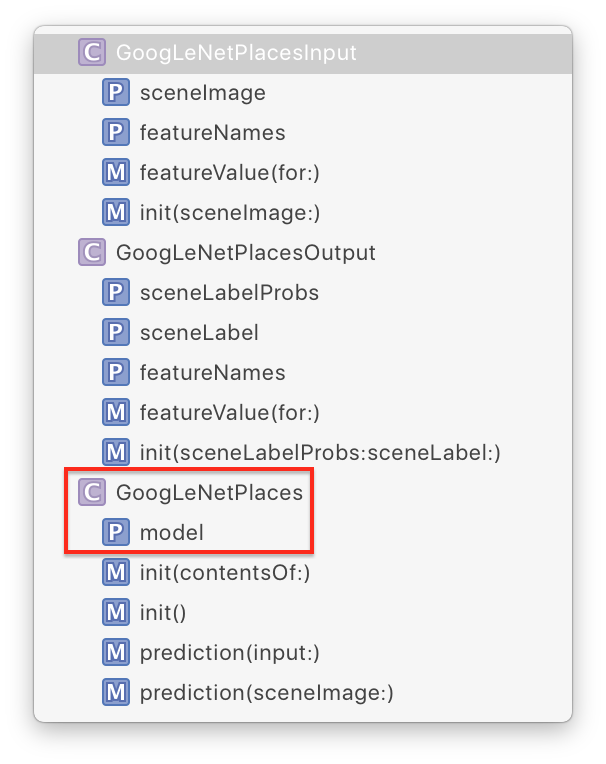
Xcode сгенерировал input (входные) и output (выходные) классы (это GoogLeNetPlacesInput и GoogLeNetPlacesOutput), а также основной класс GoogLeNetPlaces, который имеет свойство model и два метода prediction.
GoogLeNetPlacesInput имеет свойство sceneImage типа CVPixelBuffer. Что это такое!?, Возможно вы крикнули про себя, но не бойтесь, инфраструктура Vision позаботится о преобразовании наших привичных форматов изображений в нужный тип input (ввод). :]
Система Vision также преобразовывает свойства GoogLeNetPlacesOutput в свой собственный тип results и управляет вызовами методов prediction, поэтому из всего этого сгенерированного кода, ваш код будет использовать только свойство model.
Обертка модели Core ML в модель Vision
Ура, теперь приступим к написанию кода! Откройте ViewController.swift и импортируйте следующие два фреймворка, прям под import UIKit:
import CoreML
import Vision
Затем добавьте следующий extension, добавьте его после реализованного extension IBActions (// MARK: - IBActions):
// MARK: - Methods
extension ViewController {
func detectScene(image: CIImage) {
answerLabel.text = "detecting scene..."
// Load the ML model through its generated class
guard let model = try? VNCoreMLModel(for: GoogLeNetPlaces().model) else {
fatalError("can't load Places ML model")
}
}
}
Что мы сделали:
Сначала вы показываете сообщение, чтобы пользователь понял, что сейчас что-то происходит (это "detecting scene...").
Назначенный инициализатор в GoogLeNetPlaces выдаст ошибку, если мы не будем использовать try при его создании, так что не будем этим пренебрегать. :)
VNCoreMLModel - это просто контейнер для модели Core ML, используемой в запросах Vision.
Работа Vision заключается в создание модели, это создание одного или нескольких запросов, а затем создание и запуск обработчика запросов. Поздравляю! Вы только что создали модель, поэтому следующим шагом будет уже создание запроса.
Добавьте в конце следующий код, внутри метода detectScene (image :):
// Create a Vision request with completion handler
let request = VNCoreMLRequest(model: model) { [weak self] request, error in
guard let results = request.results as? [VNClassificationObservation],
let topResult = results.first else {
fatalError("unexpected result type from VNCoreMLRequest")
}
// Update UI on main queue
let article = (self?.vowels.contains(topResult.identifier.first!))! ? "an" : "a"
DispatchQueue.main.async { [weak self] in
self?.answerLabel.text = "\(Int(topResult.confidence * 100))% it's \(article) \(topResult.identifier)"
}
}
VNCoreMLRequest - это запрос на анализ изображения, который использует модель Core ML для выполнения данной работы. Когда обработка завершилась, мы получаем объекты request и error.
Потом мы проверяем, что request.results представляет собой массив объектов VNClassificationObservation, это то, что возвращается фрэимворком Vision, в то время как модель Core ML является скорее классификатором, чем процессором обработки изображения или прогнозированием. GoogLeNetPlaces тоже является классификатором, потому как он прогнозирует, но только одну особенность: классификацию сцен изображения.
VNClassificationObservation имеет два свойства: identifier - тип String и confidence – число между 0 и 1 – это вероятность того, насколько информация о классификации угадана верно. В будущем при использовании модели распознавания объекта, вы, скорее всего, будете обращать внимание только на те объекты, у которых confidence будет превышает какой-либо процент, к примеру 30% или больше.
Итак, вернемся к нашему проекту, далее вы берете первый результат, который будет иметь наивысшее значение confidence, и устанавливаете ему неопределенный артикль – «an» или «a», в зависимости от первого пришедшего слова из identifer. Теперь, вы попадаете обратно в main queue, чтобы обновить наш текстовый label (UILabel). Скоро вы увидите, что работа по классификации происходит не в main queue, потому что она может замедлить работу нашего приложения.
На третьем шаге у нас это создание и запуск обработчика запросов.
Добавьте еще вконце один код, внутри метода detectScene (image :):
// Run the Core ML GoogLeNetPlaces classifier on global dispatch queue
let handler = VNImageRequestHandler(ciImage: image)
DispatchQueue.global(qos: .userInteractive).async {
do {
try handler.perform([request])
} catch {
print(error)
}
}
VNImageRequestHandler является стандартным обработчиком запросов в фрэймворке Visio. Он не относится к модели Core ML. Вы даете ему изображение, которое пришло в detectScene (image :) в качестве аргумента. И затем запускается обработчик, вызывая его метод perform, передавая массив запросов. В нашем случае у вас есть только один запрос. Метод perform будет выдавать ошибку, если вы не определите его с помощь конструкции try-catch.
Использование модели для классификации сцен
Ух, было много кода! Теперь вам осталось только вызвать метод detectScene (image :) в двух местах.
Добавьте вконце следующий код, внутри метода viewDidLoad() и imagePickerController(_: didFinishPickingMediaWithInfo :):
guard let ciImage = CIImage(image: image) else {
fatalError("couldn't convert UIImage to CIImage")
}
detectScene(image: ciImage)
Давайте запустим наш проект. Это не займет много времени, чтобы уже можно было увидеть наш результат по классификации:
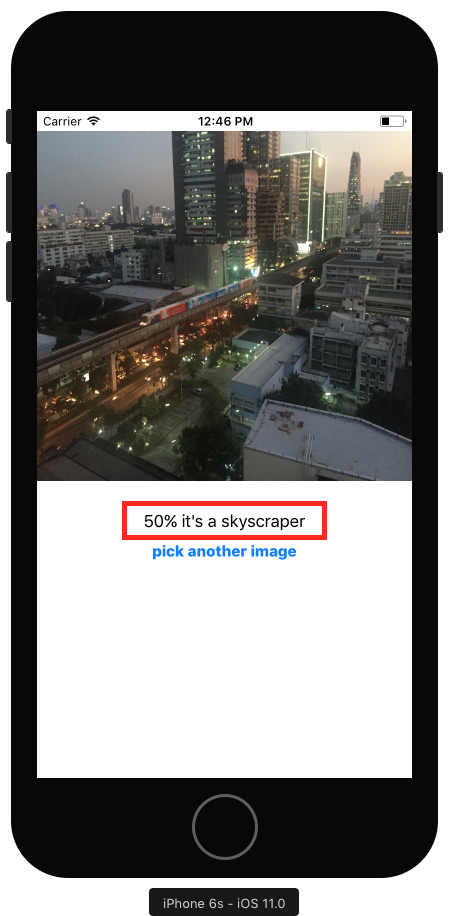
Итак, у нас 50%, что это небоскреб. Согласен, на изображении видны небоскребы. Но также изображен и поезд. Нажмите на кнопку и выберите первое изображение в библиотеке фотографий: например крупный план листьев, покрытые лучами солнцем:
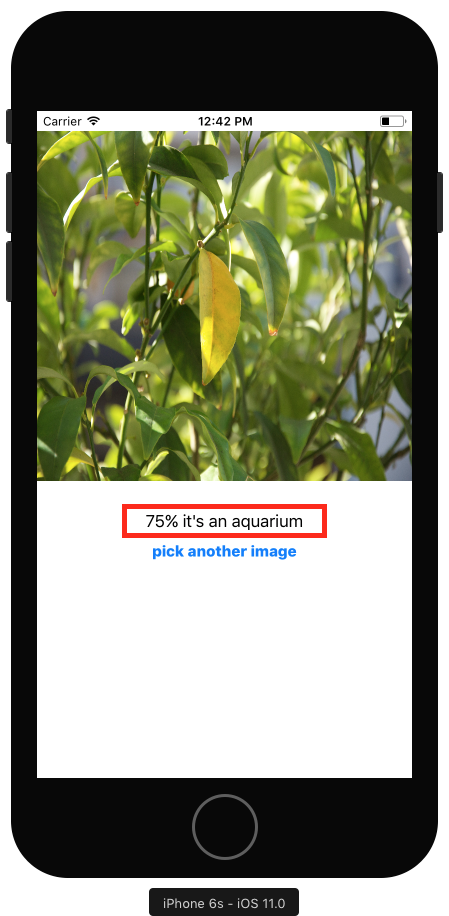
Хм, странно конечно, что такой высокий процент, что это аквариум - 75%, если конечно вы плохо видите, вы можете представить, что это все таки и есть аквариум, а вокруг плавают Немо или Дори? :] Шутка, но, по крайней мере, вы теперь точно знаете, что артикли «а» и «an» работают правильно. ;]
Взгляд на образец приложения Core ML от Apple
Этот учебный проект примерно похож на проект представленный для WWDC 2017 Session 506 Vision Framework: Building on Core ML. Приложение Vision + ML Example использует классификатор MNIST, который распознает рукописные цифры – это полезно для автоматизации почтовой сортировки. Он также использует собственный метод визуализации VNDetectRectanglesRequest и включает в себя Core Image, чтобы была возомжность исправить обнаруженные прямоугольники.
Вы также можете загрузить другой образец проекта на странице документации Core ML. Inputs (Входы) в моделе MarsHabitatPricePredictor это просто цифры, поэтому код использует методы и свойства MarsHabitatPricer напрямую, вместо того, чтобы обертывать модель в модели Vision. Понемногу изменяя параметры, можно легко видеть, что модель представляет собой просто линейную регрессию:
137 * solarPanels + 653.50 * greenHouses + 5854 * acres
А что дальше?
Дальше, вы можете продолжить изучать наши туториалы по мере их появления, а также, параллельно читать перевод официальной книги по языку программирования Swift. И, для более подробного изучения языка, вы можете пройти наши курсы!
Урок подготовил: Просвиряков Вадим





