
 Моё обучение
Моё обучение Работы выпускников
Работы выпускников О проекте
О проекте Контакты
Контакты Отзывы
Отзывы



Это руководство познакомит вас с CoreML и Vision, двумя передовыми фреймворками iOS, а также с тем, как можно точно настроить модель прямо на устройстве.
Apple выпустила Core ML и Vision в iOS 11. Core ML дает разработчикам возможность использовать модели машинного обучения в своих приложениях. Это позволяет создавать интеллектуальные фичи на устройстве, например, определение каких-либо объектов.
В Core ML 3, начиная с iOS 13, было добавлено on-device обучение и новые способы персонализации вывода.
В этом уроке вы узнаете, как можно тонко настроить модель на устройстве с помощью фреймворков Core ML и Vision. Вы начнете с приложения Vibes, которое генерирует цитаты для выбранного изображения. Оно также позволяет добавлять ваши любимые смайлики с помощью шорткатов после обучения модели.
Давайте начнем
Чтобы начать работу, скачайте дополнительные материалы к статье в нижней части этого туториала. Внутри zip-файла, вы найдете две папки: starter и final, соответствующие начальному и конечному проекту данного туториала. Теперь дважды щелкните на Vibes.xcodeproj в стартовом проекте, чтобы открыть его в Xcode.
Запустите проект, и вы увидите следующее:

Нажмите на значок камеры и выберите фотографию из библиотеки, чтобы увидеть цитату. Затем нажмите на иконку стикера и выберите любой из появившихся, чтобы добавить его к изображению. Переместите стикер туда, куда хотите:
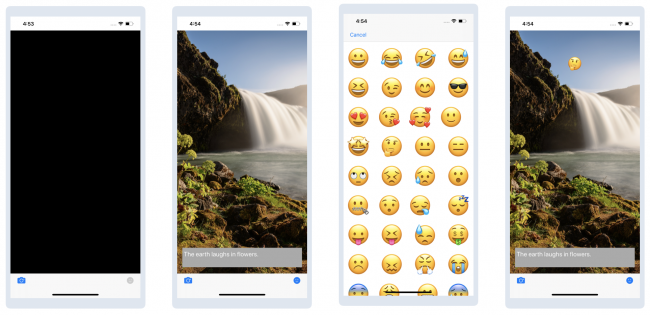
Здесь есть два момента, которые вы можете улучшить:

- Цитата выбирается случайным образом. Как насчет отображения цитаты, которая будет связана с выбранным изображением?
- Добавление стикеров занимает слишком много времени. Что, если бы вы могли создать сочетание клавиш для стикеров, которые вы используете чаще всего?
Ваша цель в этом туториале - использовать машинное обучение для решения этих двух задач.
Что такое машинное обучение?
Если вы новичок в машинном обучении, пришло время рассмотреть некоторые общие термины.
Искусственный интеллект, или ИИ - это способность машины программно имитировать человеческие действия и мысли.
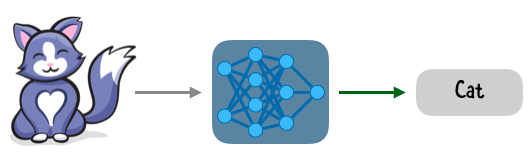
Машинное обучение или ML (machine learning) - это подмножество ИИ, которое обучает машины выполнять определенные задачи. Например, вы можете использовать ML для обучения машины распознавать кошку на изображении или переводить текст с одного языка на другой.
Глубокое обучение - это один из методов обучения машины. Эта техника имитирует человеческий мозг, который состоит из нейронов, организованных в сеть. Глубокое обучение обучает искусственную нейронную сеть на основе предоставленных данных.
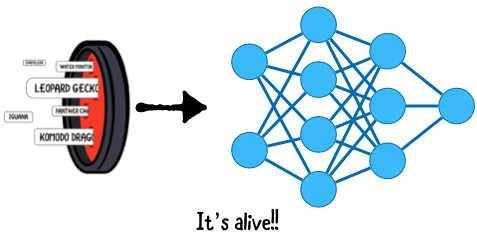
Допустим, вы хотите, чтобы машина распознала кошку на изображении. Вы можете “накормить” машину большим количеством изображений, вручную подписывая “кот” и “не кот”, затем построить модель, которая может делать точные предположения или прогнозы.
Тренировка с моделями
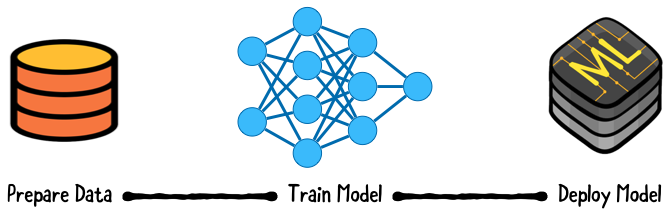
Apple определяет модель как ”результат применения алгоритма машинного обучения к набору обучающих данных". Представьте себе модель как функцию, которая принимает входные данные, выполняет определенную операцию наилучшим образом с этими входными данными, такую как обучение, а затем выполняет прогнозирование и классификацию. После выполнения предыдущих этапов эта функция производит соответствующий выходной сигнал.
Обучение с помеченными данными называется supervised learning. Вам нужно много хороших данных, чтобы построить хорошую модель. Что значит хороших данных? Это означает, что обучающие данные, которые вы поставляете в нейронную сеть, должны быть похожи на те данные, для которых вы обучаете эту нейронную сеть.
Если вы хотите, чтобы ваша модель распознавала всех кошек, но “кормите” ее только кошками определенной породы, то во время использования такой нейронной сети могут быть пропущены кошки других пород. Обучение с использованием необъективных данных может привести к нежелательным результатам.

Обучение требует больших вычислительных затрат и часто выполняется на серверах. Благодаря своим параллельным вычислительным возможностям, видеокарты, обычно, ускоряют процесс.
После завершения обучения модель можно развернуть в рабочей среде для выполнения прогнозов или выводов на основе реальных данных.
Вывод не так требователен к вычислениям, как обучение. Однако, в прошлом мобильным приложениям приходилось совершать удаленные вызовы на сервер для вывода модели.
Прогресс в области производительности мобильных чипов открыл дверь для персонализации вывода информации на устройстве. Эти преимущества включают в себя снижение задержки, меньшую зависимость от сети и улучшение конфиденциальности. Но вы получаете увеличение размера приложения и более быструю разрядку батареи из-за вычислительной нагрузки.
Это руководство научит вас использовать Core ML для on-device вывода, а также для on-device обучения.
Фреймворки и инструменты Apple для машинного обучения
Core ML работает с предметно-ориентированными фреймворками, такими как Vision, который нужен нам для анализа изображений. Vision предоставляет высокоуровневые API для запуска алгоритмов компьютерного зрения на изображениях и видео. Vision может классифицировать изображения с помощью встроенной модели, предоставляемой Apple, или пользовательских моделей Core ML.
Core ML построен поверх примитивов более низкого уровня: ускорение с помощью BNNS и Metal Performance Shaders:
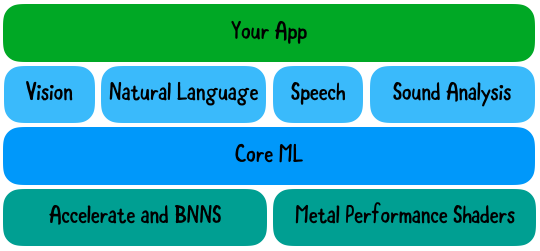
Другие предметно-ориентированные фреймворки, с которыми работает Core ML - Natural Language для обработки текста и Sound Analysis для идентификации звуков в аудио.
Интеграция модели Core ML в ваше приложение
Для интеграции Core ML необходима модель в формате Core ML Model. Apple предоставляет предварительно подготовленные модели, которые можно использовать для таких задач, как классификация изображений. Если эти модели у вас не работают, вы можете найти модели, созданные сообществом или создать свои собственные.
Для вашего первого улучшения для Vibes вам нужна модель, которая делает классификацию изображений. Модели доступны с различной степенью точности и размером модели. Вы будете использовать SqueezeNet, небольшую модель, обученную распознавать обычные объекты.
Перетащите SqueezeNet.mlmodel из директории Models в папку Models вашего проекта Xcode:
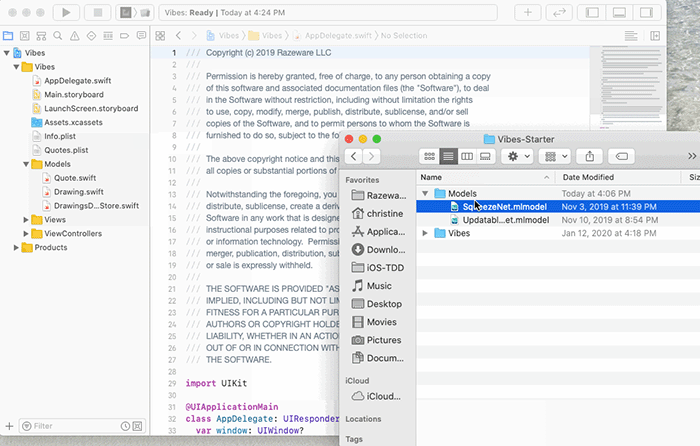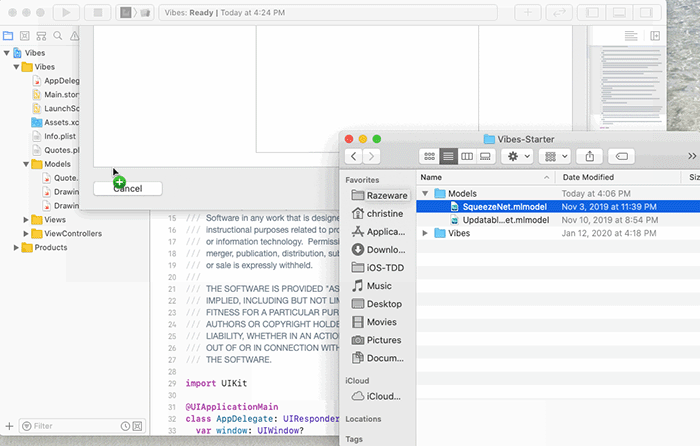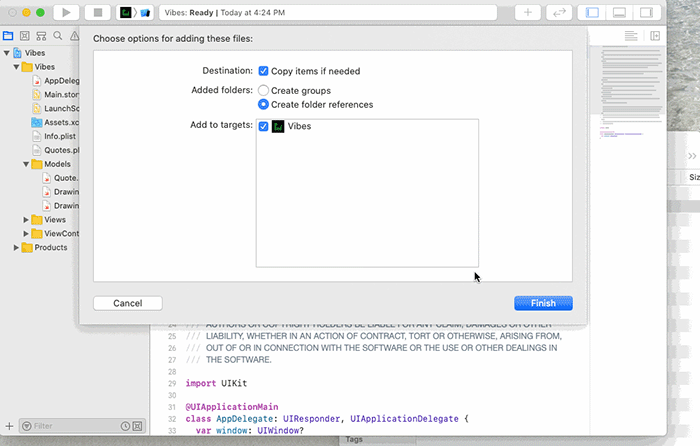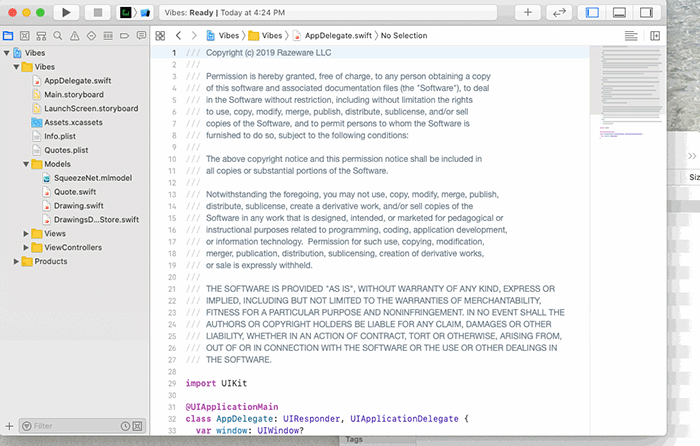
Выберите SqueezeNet.mlmodel и просмотрите сведения о модели в навигаторе проекта:
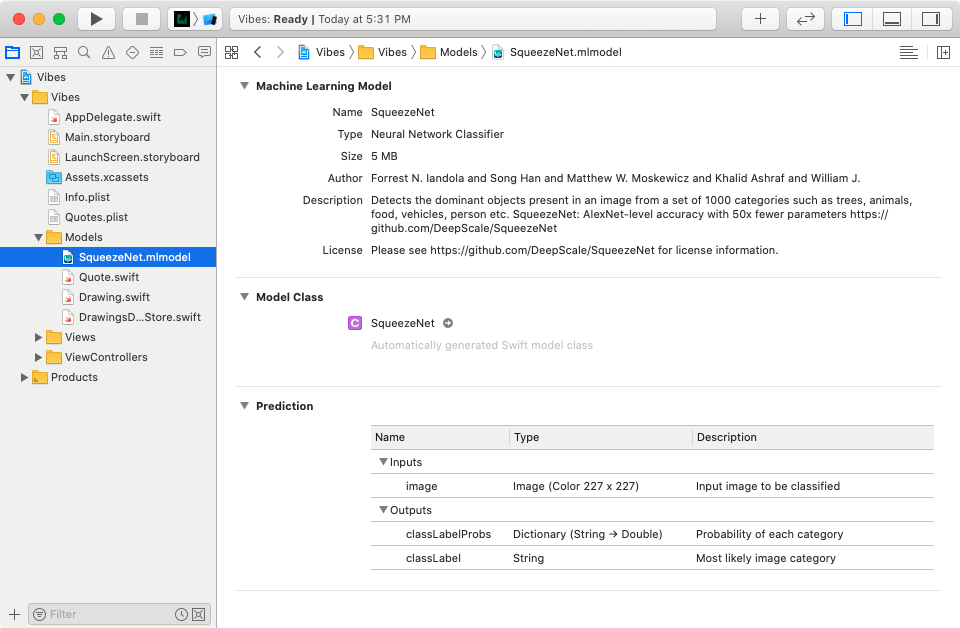
В разделе Prediction перечислены ожидаемые входные и выходные данные:
- Входные данные Image ожидают изображение размером 227×227.
- Существует два типа выходных данных: classLabelProbs возвращает словарь с вероятностями для категорий. classLabel возвращает категорию с наибольшей вероятностью.
Нажмите на стрелку рядом с названием модели:
Xcode автоматически генерирует файл для модели, который включает классы для входного, выходного и основного классов. Основной класс включает в себя различные методы для составления прогнозов.
Стандартный рабочий процесс фреймворка Vision:
Создание модели Core ML
Создание одного или нескольких запросов.
Создание и запуск обработчика запросов
Вы создали свою SqueezeNet.mlmodel модель. Далее вы создадите запрос.
Создание запроса
Перейдите в раздел CreateQuoteViewController.swift и добавьте следующей код после import UIKit:
import CoreML
import VisionVision помогает работать с изображениями, например, преобразовывать их в нужный формат.
Добавьте следующее свойство:
// 1
private lazy var classificationRequest: VNCoreMLRequest = {
do {
// 2
let model = try VNCoreMLModel(for: SqueezeNet().model)
// 3
let request = VNCoreMLRequest(model: model) { request, _ in
if let classifications =
request.results as? [VNClassificationObservation] {
print("Результат классификации: \(classifications)")
}
}
// 4
request.imageCropAndScaleOption = .centerCrop
return request
} catch {
// 5
fatalError("Failed to load Vision ML model: \(error)")
}
}()Описание того, что происходит:
- Определяется запрос на анализ изображений, который создается при первом обращении.
- Создается экземпляр модели.
- Создается экземпляр объекта запроса анализа изображений на основе модели. Обработчик завершения получает результаты классификации и выводит их.
- Используем Vision, для того, чтобы обрезать входное изображение, чтобы удовлетворить ожидания модели.
- Обрабатываются ошибки загрузки модели путем прекращения работы приложения. Модель является частью приложения, поэтому в идеале этого кейса никогда не должно произойти.
Интеграция запроса
Добавьте следующий код в конец приватного расширения CreateQuoteViewController:
func classifyImage(_ image: UIImage) {
// 1
guard let orientation = CGImagePropertyOrientation(
rawValue: UInt32(image.imageOrientation.rawValue)) else {
return
}
guard let ciImage = CIImage(image: image) else {
fatalError("Unable to create \(CIImage.self) from \(image).")
}
// 2
DispatchQueue.global(qos: .userInitiated).async {
let handler =
VNImageRequestHandler(ciImage: ciImage, orientation: orientation)
do {
try handler.perform([self.classificationRequest])
} catch {
print("Failed to perform classification.\n\(error.localizedDescription)")
}
}
}Вот что делает этот метод запроса классификации:
Получает ориентацию изображения и представление в CIImage.
Запускает асинхронный запрос классификации в фоновом режиме. Вы создаете обработчик для выполнения запроса Vision, а затем назначаете его выполнение.
Наконец, добавьте следующий код в конец метода imagePickerController(_:didFinishPickingMediaWithInfo:):
classifyImage(image)Этот код запускает классификационный запрос, когда пользователь выбирает изображение.
Запустите приложение. Нажмите на значок камеры и выберите фотографию. Визуально ничего не поменялось:

Однако, консоль должна перечислить необработанные результаты классификации:
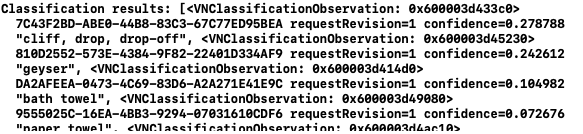
В этом примере классификатор имеет 27,9% уверенности в том, что на изображении cliff, drop, drop-off (отвесная скала, падение, перепад). Найдите classificationRequest и замените print приведенным ниже кодом для регистрации результатов:
let topClassifications = classifications.prefix(2).map {
(confidence: $0.confidence, identifier: $0.identifier)
}
print("Top classifications: \(topClassifications)")Запустите приложение, а затем выберите фотографию. Консоль должна вывести топовые результаты:

Теперь вы можете использовать извлеченные детали прогноза, чтобы показать цитату, связанную с изображением.
Добавление цитаты
В imagePickerController(_: didFinishPickingMediaWithInfo:) удалите следующее:
if let quote = getQuote() {
quoteTextView.text = quote.text
}Этот код нужен для показа случайной цитаты. Давайте его удалим, так как он больше нам не пригодится.
Далее мы с вами добавим логику, чтобы получить цитату, используя результаты
VNClassificationObservation. Добавьте следующее в расширение CreateQuoteViewController:
func processClassifications(for request: VNRequest, error: Error?) {
DispatchQueue.main.async {
// 1
if let classifications =
request.results as? [VNClassificationObservation] {
// 2
let topClassifications = classifications.prefix(2).map {
(confidence: $0.confidence, identifier: $0.identifier)
}
print("Top classifications: \(topClassifications)")
let topIdentifiers =
topClassifications.map {$0.identifier.lowercased() }
// 3
if let quote = self.getQuote(for: topIdentifiers) {
self.quoteTextView.text = quote.text
}
}
}
}Вот, что происходит в приведенном выше коде:
- Этот метод обрабатывает результаты запроса классификации изображений.
- Метод извлекает два лучших прогноза. Этот код вы уже видели ранее.
- Прогнозы поступают в getQuote(for:), чтобы получить соответствующую цитату.
Этот метод выполняется в основной очереди, так как работа с интерфейсом, в частности его обновление, должна всегда происходить в основном потоке.
Наконец, вызовите следующий метод из classificationRequest и измените Request на следующий:
let request = VNCoreMLRequest(model: model) { [weak self] request, error in
guard let self = self else {
return
}
self.processClassifications(for: request, error: error)
}Здесь завершающий обработчик вызывает новый метод для обработки результатов.
Запустите приложение. Выберите фотографию с лимоном или лимонным деревом. При необходимости загрузите ее из браузера. Вы должны увидеть цитату про лимон, а не рандомную:

Убедитесь, что консоль регистрирует соответствующую классификацию:

Попробуйте повторить процесс несколько раз, чтобы проверить, что результаты идентичны.
Поздравляю! Вы узнали, как использовать Core ML для вывода модели на устройстве.

Персонализация модели на устройстве
С помощью Core ML 3 вы можете точно настроить обновляемую модель на устройстве во время выполнения. Это означает, что вы можете персонализировать опыт использования для каждого пользователя.
On-device персонализация - это идея, лежащая в основе Face ID. Apple может предоставить общую модель на устройство, которая распознает лицо. Во время настройки Face ID каждый пользователь может точно настроить модель для распознавания именно своего лица.
Нет смысла отправлять эту обновленную модель обратно в Apple для остальных пользователей. Это подчеркивает преимущество конфиденциальности, которую приносит on-device персонализация.
Обновляемая модель - это базовая модель ML, у которой есть соответствующая маркировка. Вы также определяете входные данные для обучения, которые будете использовать для обновления модели.
k-Nearest Neighbors (ближайшие соседи)
Вы улучшите приложение Vibes с помощью модели обновляемого рисующего классификатора. Классификатор распознает новые рисунки на основе k-Nearest Neighbors или k-NN.
k-NN алгоритм предполагает, что схожие между собой объекты находятся близко друг к другу.

Происходит это путем сравнения векторов признаков. Вектор признака или свойства содержит важную информацию, которая описывает характеристики объекта. Примером векторного признака является цвет RGB, представленный R, G и B отдельно.
Сравнение расстояния между векторами признаков - это простой способ увидеть, похожи ли два объекта. k-NN классифицирует входные данные, используя их k-nearest neighbors (то есть ближайших соседей).
В приведенном ниже примере показан разброс рисунков, классифицированных как квадраты и круги. Допустим, вы хотите узнать, к какой группе относится новый таинственный рисунок в красном цвете:
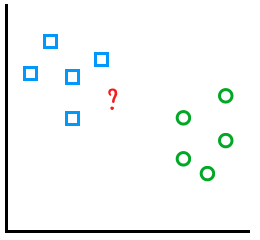
Выбор k = 3 предсказывает, что этот рисунок представляет собой квадрат:
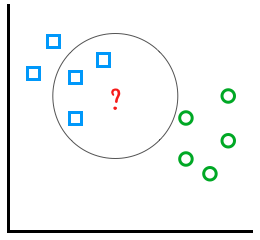
Модели k-NN просты и быстры. Вам не нужно много примеров, чтобы обучить их. Однако производительность может замедлиться, если для анализа будет предоставлено множество данных.
k-NN - это одна из типов моделей, которые Core ML поддерживает для обучения. Приложение Vibes использует обновляемый классификатор рисунков с:
- Нейронной сетью, действующей как экстрактор свойств. Она умеет распознавать рисунки. Вам нужно извлечь свойства для модели k-NN.
- Моделью k-NN для персонализации on-device рисунков.
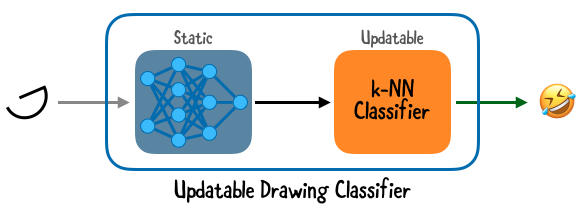
В Vibes пользователь может добавить шорткат, выбрав эмодзи, а затем нарисовать три примера. Вы будете обучать модель с эмодзи в качестве ярлыка и рисунками в качестве учебных данных.
Настройка процесса для обучения рисованию
Во-первых, подготовьте экран к получению пользовательских данных, для того, чтобы тренировать нашу модель:
- Добавления экрана, который будет отображаться при выборе эмодзи.
- Добавления действия при нажатии “сохранить”.
- Удаление UIPanGestureRecognizer из stickerLabel.
Откройте AddStickerViewController.swift и в collectionView(_:didSelectItemAt:) замените вызов performSegue(withIdentifier:sender:) следующим:
performSegue(withIdentifier: "AddShortcutSegue", sender: self)Этим мы создаем переход к отображению примеров рисунков, когда пользователь выбирает эмодзи.
Затем откройте AddShortcutViewController.swift и добавьте следующий код для реализации savePressed(_:):
print("Training data ready for label: \(selectedEmoji ?? "")")
performSegue(
withIdentifier: "AddShortcutUnwindSegue",
sender: self)Это настраивает переход к главному экрану, когда пользователь нажимает Save.
Наконец, откройте CreateQuoteViewController.swift и в addStickerToCanvas(_: at:) удалите следующий код:
stickerLabel.isUserInteractionEnabled = true
let panGestureRecognizer = UIPanGestureRecognizer(
target: self,
action: #selector(handlePanGesture(_:)))
stickerLabel.addGestureRecognizer(panGestureRecognizer)Мы с вами удалили код, позволяющий пользователю перемещать стикеры. Этот код нам нужен был тогда, когда пользователь не мог контролировать расположение стикера.
Запустите приложение, а затем выберите фотографию. Нажмите на значок стикера и выберите эмодзи. Вы увидите выбранные вами эмодзи, а также три поля для рисования:

Теперь нарисуйте три одинаковых изображения. Убедитесь, что есть возможность все сохранить после третьего рисунка:

Затем нажмите Save и убедитесь, что выбранный смайлик зарегистрирован в консоли:

Пришло время переключить свое внимание на код, вызывающий шорткат.
Добавление шортката Drawing View
Пришло время подготовить вью рисунка, выполнив следующие действия:
- Во-первых, объявите DrawingView.
- Затем добавьте вью рисунка в основной вью.
- Затем вызовите addCanvasForDrawing из viewDidLoad().
- Наконец, очистите холст при выборе изображения.
Откройте CreateQuoteViewController.swift и добавьте следующее свойство после объявления IBOutlet:
var drawingView: DrawingView!Это содержит вью, в котором пользователь рисует ярлык.
Затем добавьте следующий код для реализации addCanvasForDrawing():
drawingView = DrawingView(frame: stickerView.bounds)
view.addSubview(drawingView)
drawingView.translatesAutoresizingMaskIntoConstraints = false
NSLayoutConstraint.activate([
drawingView.topAnchor.constraint(equalTo: stickerView.topAnchor),
drawingView.leftAnchor.constraint(equalTo: stickerView.leftAnchor),
drawingView.rightAnchor.constraint(equalTo: stickerView.rightAnchor),
drawingView.bottomAnchor.constraint(equalTo: stickerView.bottomAnchor)
])Здесь вы создаете экземпляр DrawingView и добавляете его в основной вью. Вы устанавливаете констрейнты Auto Layout таким образом, чтобы она перекрывала только вид стикера.
Затем добавьте следующее в конец viewDidLoad():
addCanvasForDrawing()
drawingView.isHidden = trueЗдесь вы добавляете вью рисунка и должны убедиться, что он изначально был скрыт.
Теперь в imagePickerController(_:didFinishPickingMediaWithInfo:) добавьте следующий сразу после того как мы активируем addStickerButton:
drawingView.clearCanvas()
drawingView.isHidden = falseЗдесь вы удаляете все предыдущие рисунки и открываете вью рисунка, чтобы пользователь мог добавлять стикеры.
Запустите приложение, а затем выберите фотографию. Мышкой или пальцем попробуйте рисовать на выбранном изображении:

Уже достигнут определенный прогресс. Идем дальше!
Составление модели прогноза
Перетащите UpdatableDrawingClassifier.mlmodel из начальной директории Models в папку Models вашего проекта в Xcode:
Теперь выберите UpdatableDrawingClassifier.mlmodel в Project navigator. В разделе Update вы можете увидеть два входа, ожидаемых моделью во время обучения. Один из них представляет собой рисунок, а другой - эмодзи-метку:
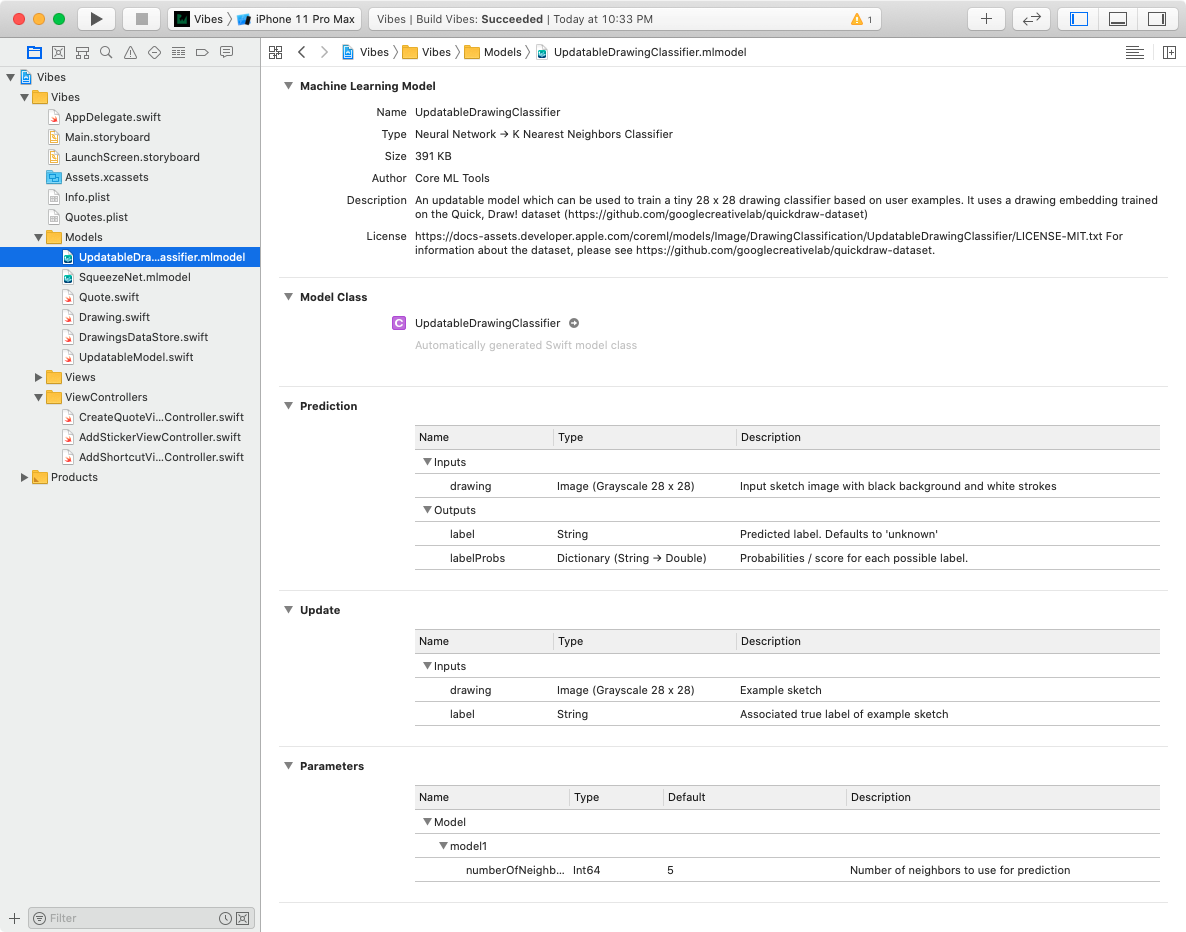
В разделе Prediction (прогнозирования) перечислены входные и выходные данные. Формат ввода drawing совпадает с форматом, используемым во время обучения. Вывод label представляет собой прогнозируемую эмодзи-метку.
Выберите папку Model в навигаторе проектов Xcode. Затем File ▸ New ▸ File…, выберите iOS ▸ Source ▸ Swift File и нажмите кнопку Next. Назовите файл UpdatableModel.swift и нажмите кнопку Create.
Теперь замените импорт Foundation следующим:
import CoreMLЭтот код позволяет нам использовать фреймворк машинного обучения.
Теперь добавьте следующее расширение в конец файла:
extension UpdatableDrawingClassifier {
var imageConstraint: MLImageConstraint {
return model.modelDescription
.inputDescriptionsByName["drawing"]!
.imageConstraint!
}
func predictLabelFor(_ value: MLFeatureValue) -> String? {
guard
let pixelBuffer = value.imageBufferValue,
let prediction = try? prediction(drawing: pixelBuffer).label
else {
return nil
}
if prediction == "unknown" {
print("No prediction found")
return nil
}
return prediction
}
}Этот код расширяет UpdatableDrawingClassifier, который является сгенерированным классом модели. Вот что делает ваш код:
- добавляет переменную imageConstraint, чтобы убедиться, что изображение соответствует тому, что ожидает модель.
- добавляет метод predictLabelFor(_:) для вызова метода прогнозирования модели с отображением рисунка CVPixelBuffer. Этот метод возвращает прогнозируемый лейбл или nil, если нет никакого прогноза.
Обновление модели
Добавьте следующее после объявления импорт:
struct UpdatableModel {
private static var updatedDrawingClassifier: UpdatableDrawingClassifier?
private static let appDirectory = FileManager.default.urls(
for: .applicationSupportDirectory,
in: .userDomainMask).first!
private static let defaultModelURL =
UpdatableDrawingClassifier.urlOfModelInThisBundle
private static var updatedModelURL =
appDirectory.appendingPathComponent("personalized.mlmodelc")
private static var tempUpdatedModelURL =
appDirectory.appendingPathComponent("personalized_tmp.mlmodelc")
private init() { }
static var imageConstraint: MLImageConstraint {
let model = updatedDrawingClassifier ?? UpdatableDrawingClassifier()
return model.imageConstraint
}
}Структура представляет вашу обновляемую модель. Определение здесь устанавливает свойства для модели. К ним относятся расположения исходной скомпилированной модели и сохраненной модели.
Заметка
Core ML использует скомпилированный файл модели с расширением .mlmodelc, который на самом деле является папкой.
Загрузка модели в память
Теперь добавьте private расширение после определения структуры:
private extension UpdatableModel {
static func loadModel() {
let fileManager = FileManager.default
if !fileManager.fileExists(atPath: updatedModelURL.path) {
do {
let updatedModelParentURL =
updatedModelURL.deletingLastPathComponent()
try fileManager.createDirectory(
at: updatedModelParentURL,
withIntermediateDirectories: true,
attributes: nil)
let toTemp = updatedModelParentURL
.appendingPathComponent(defaultModelURL.lastPathComponent)
try fileManager.copyItem(
at: defaultModelURL,
to: toTemp)
try fileManager.moveItem(
at: toTemp,
to: updatedModelURL)
} catch {
print("Error: \(error)")
return
}
}
guard let model = try? UpdatableDrawingClassifier(
contentsOf: updatedModelURL) else {
return
}
updatedDrawingClassifier = model
}
}Этот код загружает обновленную скомпилированную модель в память. Затем добавьте следующее расширение сразу после определения структуры:
extension UpdatableModel {
static func predictLabelFor(_ value: MLFeatureValue) -> String? {
loadModel()
return updatedDrawingClassifier?.predictLabelFor(value)
}
}Метод predict загружает модель в память, а затем вызывает метод predict, уже добавленный в расширение.
Теперь откройте Drawing.swift и добавьте следующее после импорта PencilKit:
import CoreMLЭто необходимо для подготовки входных данных для прогноза.
Подготовка прогноза
Core ML ожидает, что вы предоставите входные данные для прогноза в виде объекта MLFeatureValue. Этот объект включает в себя как значение данных, так и их тип.
Находясь в Drawing.swift, добавьте следующее свойство в структуру:
var featureValue: MLFeatureValue {
let imageConstraint = UpdatableModel.imageConstraint
let preparedImage = whiteTintedImage
let imageFeatureValue =
try? MLFeatureValue(cgImage: preparedImage, constraint: imageConstraint)
return imageFeatureValue!
}Это определит вычисляемое свойство, которое устанавливает значение свойства рисунка. Значение свойства основано на отображении изображения в белом цвете и констрейнте изображения модели.
Теперь, когда вы подготовили входные данные, вы можете сосредоточиться на запуске прогноза.
Во-первых, откройте CreateQuoteViewController.swift и добавьте расширение DrawingViewDelegate в конец файла:
extension CreateQuoteViewController: DrawingViewDelegate {
func drawingDidChange(_ drawingView: DrawingView) {
// 1
let drawingRect = drawingView.boundingSquare()
let drawing = Drawing(
drawing: drawingView.canvasView.drawing,
rect: drawingRect)
// 2
let imageFeatureValue = drawing.featureValue
// 3
let drawingLabel =
UpdatableModel.predictLabelFor(imageFeatureValue)
// 4
DispatchQueue.main.async {
drawingView.clearCanvas()
guard let emoji = drawingLabel else {
return
}
self.addStickerToCanvas(emoji, at: drawingRect)
}
}
}Напомним,что вы добавили DrawingView для рисования шорткатов стикеров. В этом коде вы подписываетесь под протокол, чтобы получать уведомления всякий раз, когда меняется рисунок. Реализация выполняет следующее:
- Создает экземпляр Drawing с информацией о рисунке и ограничивающем рисунок квадрате.
- Создает свойство объекта для входных данных прогноза рисунка.
- Делает прогноз, чтобы получить эмодзи, соответствующий рисунку.
- Обновляет вью в главной очереди, чтобы очистить холст и добавить спрогнозированный эмодзи во вью.
Затем в imagePickerController(_:didFinishPickingMediaWithInfo:) удалите следующее:
drawingView.clearCanvas()На этом этапе рисунок вы не удаляете. Это нужно будет сделать после составления прогноза.
Проверка прогноза
Далее, в addCanvasForDrawing() добавьте следующий код сразу после объявления drawingView:
drawingView.delegate = selfВью контроллер становится делегатом drawingView.
Запустите приложение, а затем выберите фотографию. Нарисуйте на холсте и убедитесь, что рисунок будет очищен, а в консоли появится запись:
Этого следовало ожидать. Вы еще не добавили шорткат для стикера.
Теперь пройдитесь по всему процессу добавления ярлыка для стикера. После того как вы вернетесь к просмотру выбранной фотографии, нарисуйте тот же ярлык:

Оп! А стикер то еще не добавлен! Вы можете проверить журнал консоли на наличие подсказок:

Если немного подумать, то можно заметить, что ваша модель понятия не имеет о стикере, который вы добавили. Пора это исправить.
Обновление модели
Вы обновляете модель, создавая MLUpdateTask. Инициализатор задачи обновления требует скомпилированный файл модели, обучающие данные и завершающий обработчик. Как правило, вы хотите сохранить обновленную модель на диск и перегрузить ее, чтобы новые прогнозы использовали самые последние данные.
Вы начнете с подготовки обучающих данных на основе шорткатов рисунков.
Вспомните, как вы создали прогнозы модели, передав входные данные MLFeatureProvider. По аналогии, вы можете обучить модель, передав входные данные так же MLFeatureProvider. Вы можете делать прогнозы для групп или тренироваться с большим количеством входных данных, передавая их в MLBatchProvider, содержащих несколько провайдеров свойств.
Во-первых, откройте DrawingDataStore.swift и замените импорт Foundation следующими:
import CoreMLЭто необходимо для настройки ввода данных для обучения Core ML.
Затем добавьте в расширение следующий метод:
func prepareTrainingData() throws -> MLBatchProvider {
// 1
var featureProviders: [MLFeatureProvider] = []
// 2
let inputName = "drawing"
let outputName = "label"
// 3
for drawing in drawings {
if let drawing = drawing {
// 4
let inputValue = drawing.featureValue
// 5
let outputValue = MLFeatureValue(string: emoji)
// 6
let dataPointFeatures: [String: MLFeatureValue] =
[inputName: inputValue,
outputName: outputValue]
// 7
if let provider =
try? MLDictionaryFeatureProvider(
dictionary: dataPointFeatures) {
featureProviders.append(provider)
}
}
}
// 8
return MLArrayBatchProvider(array: featureProviders)
}Вот пошаговый разбор этого кода:
- Инициализирован пустой массив провайдеров свойств.
- Определены имена для входных данных обучения модели.
- Перебор изображений в хранилище данных.
- Происходит оборачивание входных данных обучения рисованию в значение свойства.
- Происходит оборачивание входных данных обучения эмодзи в значение свойства.
- Создана точка входных данных обучения. Это словарь имен входных данных обучения и значений свойств.
- Создан провайдер свойства для точки данных, а также добавлен в массив свойств провайдеров.
- Наконец, создан пакетный провайдер из массива свойств провайдеров.
Теперь откройте UpdatableModel.swift и добавьте следующий метод в конец расширения UpdatableDrawingClassifier:
static func updateModel(
at url: URL,
with trainingData: MLBatchProvider,
completionHandler: @escaping (MLUpdateContext) -> Void
) {
do {
let updateTask = try MLUpdateTask(
forModelAt: url,
trainingData: trainingData,
configuration: nil,
completionHandler: completionHandler)
updateTask.resume()
} catch {
print("Couldn't create an MLUpdateTask.")
}
}Код создает задачу обновления с URL-адресом скомпилированной модели. Вы также передаете пакетный провайдер с данными обучения. Вызов resume() запускает обучение, а завершающий обработчик вызывается по завершению обучения.
Сохранение модели
Теперь добавьте следующий метод в расширение для UpdatableModel:
static func saveUpdatedModel(_ updateContext: MLUpdateContext) {
// 1
let updatedModel = updateContext.model
let fileManager = FileManager.default
do {
// 2
try fileManager.createDirectory(
at: tempUpdatedModelURL,
withIntermediateDirectories: true,
attributes: nil)
// 3
try updatedModel.write(to: tempUpdatedModelURL)
// 4
_ = try fileManager.replaceItemAt(
updatedModelURL,
withItemAt: tempUpdatedModelURL)
print("Updated model saved to:\n\t\(updatedModelURL)")
} catch let error {
print("Could not save updated model to the file system: \(error)")
return
}
}Этот вспомогательный класс выполняет работу по сохранению обновленной модели. Он принимает в MLUpdateContext, который содержит полезную информацию об обучении. Этот метод выполняет следующие действия:
- Сначала он получает обновленную модель из памяти. Модель не является исходной.
- Затем он создает промежуточную папку для сохранения обновленной модели.
- Он записывает обновленную модель во временную папку.
- Наконец, он заменяет содержимое папки модели. Перезапись существующей папки mlmodelc приведет к ошибке. Чтобы избежать ошибки, нужно сначала сохранять все в промежуточную папку, а затем скопировать ее содержимое.
Выполнение обновления
Добавьте следующий метод в расширение UpdatableModel:
static func updateWith(
trainingData: MLBatchProvider,
completionHandler: @escaping () -> Void
) {
loadModel()
UpdatableDrawingClassifier.updateModel(
at: updatedModelURL,
with: trainingData) { context in
saveUpdatedModel(context)
DispatchQueue.main.async { completionHandler() }
}
}Код загружает модель в память, а затем вызывает метод обновления, определенный в ее расширении. Завершающий обработчик сохраняет обновленную модель, а затем запускает завершающий обработчик этого метода.
Теперь откройте AddShortcutViewController.swift и замените реализацию savePressed(_:) на следующую:
do {
let trainingData = try drawingDataStore.prepareTrainingData()
DispatchQueue.global(qos: .userInitiated).async {
UpdatableModel.updateWith(trainingData: trainingData) {
DispatchQueue.main.async {
self.performSegue(
withIdentifier: "AddShortcutUnwindSegue",
sender: self)
}
}
}
} catch {
print("Error updating model", error)
}Здесь вы собрали все необходимое для обучения. После настройки обучающих данных вы запускаете фоновый поток для обновления модели. Метод update вызывает unwind-переход на главный экран.
Запустите приложение, а затем выполните действия по созданию шортката.
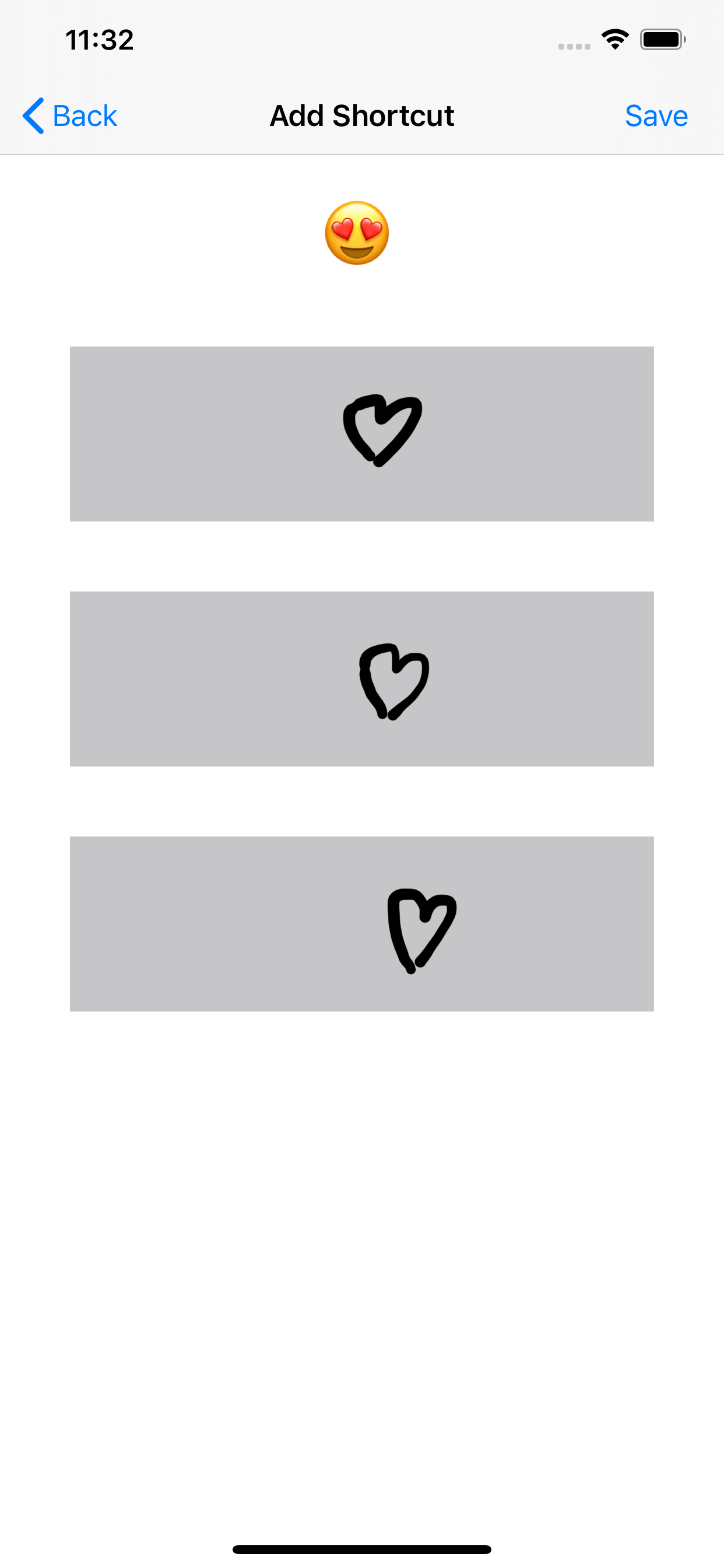
Убедитесь, что при нажатии кнопки Save консоль регистрирует обновление модели:

Нарисуйте тот же шорткат на выбранной фотографии и убедитесь, что отображается правильный эмодзи:
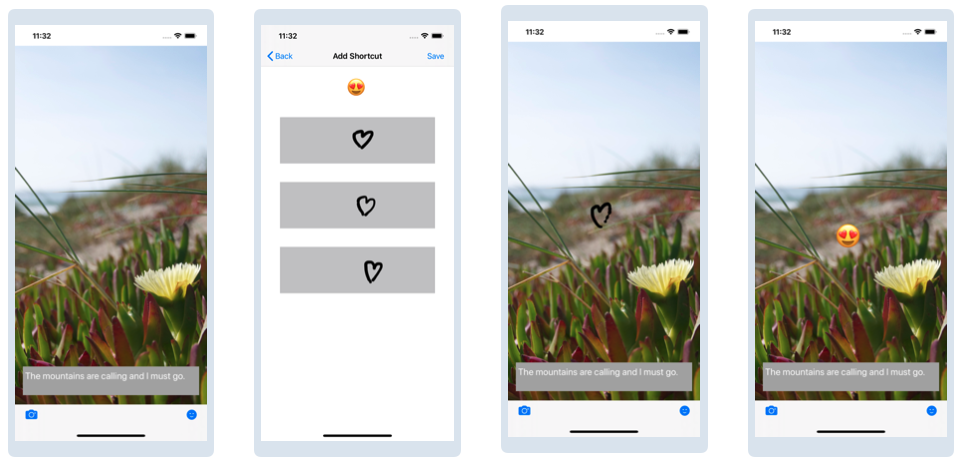
Поздравляю! Теперь Вы ниндзя машинного обучения!






